For customers running FIXEdge C++, FIX Integrated Control Center (FIXICC), or custom solutions built with the FIX Antenna SDK, we leverage cloud-native Kubernetes infrastructure to implement a cold-standby high-availability (HA) pattern that balances resilience, operational simplicity, and deterministic FIX behavior.
Supported Products
This deployment pattern applies to:
- FIXEdge C++
- FIXICC H2
- Custom solutions built with the FIX Antenna SDK
Architecture Overview
How It Works
- Kubernetes StatefulSet (replicas = 1) A StatefulSet ensures a stable identity for the FIX engine instance, including a persistent Pod name and network identity. Only one active FIX engine instance runs at any time.
- Persistent Volumes Backed by CSI FIX session logs, sequence numbers, and application state are stored on a Persistent Volume (PV) provisioned via a cloud provider’s CSI driver (e.g., AWS EBS, Azure Disk). All critical FIX session state is synchronously persisted to disk, relying on the durability guarantees of the underlying storage.
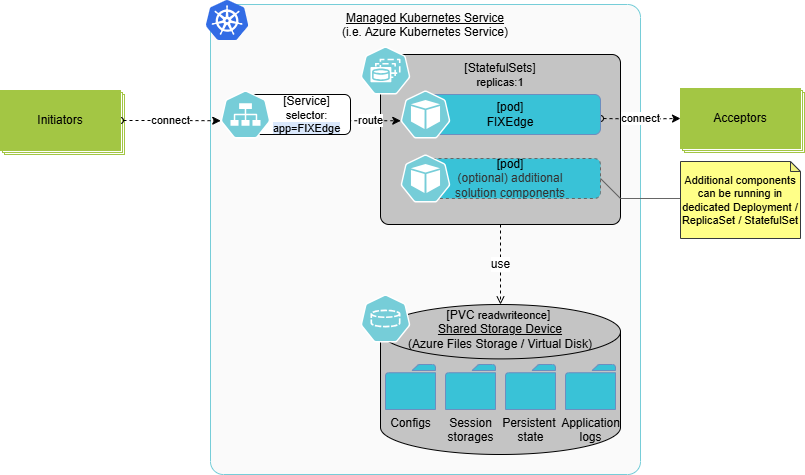
Failover Behavior
In the event of node or Pod failure:
- The Kubernetes StatefulSet controller automatically schedules a new Pod on a healthy node.
- The existing Persistent Volume is re-attached to the new Pod.
- The FIXEdge process restarts and resumes operation using the preserved on-disk session state.
- Clients reconnect via the configured LoadBalancer or service endpoint.
FIX Session Semantics During Recovery
- FIX session sequence numbers and message logs are preserved across restarts.
- Upon client reconnection, standard FIX gap detection and replay mechanisms apply.
- Messages that were in flight at the time of failure may be replayed after recovery.
- Idempotency and duplicate handling remain governed by FIX protocol semantics and client-side logic.
This approach ensures end-to-end message integrity, while maintaining deterministic and standards-compliant FIX behavior.
Client Connectivity Considerations
To achieve optimal recovery times, FIX clients should follow standard HA best practices:
- Enable automatic reconnect and retry logic
- Use appropriate heartbeat intervals to detect failures promptly
- Tune DNS TTLs or leverage direct LoadBalancer IPs to minimize reconnection delays
These practices ensure that client reconnection aligns with the engine’s rapid restart behavior.
Trade-offs
Pros
- Cloud-native resilience
Leverages Kubernetes’ built-in self-healing, scheduling, and rolling-update capabilities with minimal custom logic. - Managed persistence
CSI-backed volumes benefit from cloud-provider durability, replication, snapshotting, and restore capabilities. - Operational simplicity
Once StatefulSets and PVs are defined, standard Kubernetes workflows (kubectl, Helm, CI/CD pipelines) handle upgrades, configuration drift, and node failures. - Unified observability
Monitoring, logging, and alerting integrate seamlessly with existing Kubernetes ecosystems (Prometheus, Fluentd, OpenTelemetry, etc.).
Cons
- Cold-standby recovery latency
Failover time is bounded by PV detach/attach operations and container startup, typically on the order of 30–90 seconds, depending on cloud provider and volume characteristics. - Single-replica execution
With replicas: 1, there is no parallel processing of FIX traffic. Horizontal scaling requires sharding, multiple StatefulSets, or higher-level routing strategies. - Storage costs and cloud specificity
Persistent volumes incur ongoing costs, and CSI behavior can vary subtly across cloud providers. - Client reconnection delays
DNS propagation or load-balancer reconfiguration may introduce additional seconds of delay if TTLs and client settings are not tuned appropriately.
Positioning: When to Use This Pattern
This cold-standby StatefulSet model is well suited for:
- Regulated trading environments
- Deterministic FIX session management
- Firms prioritizing operational simplicity and protocol correctness
- Post-trade and connectivity hubs where sub-second RTO is not required
It is not intended for:
- Ultra-low-latency, sub-second RTO requirements
- True active-active FIX session processing without protocol-level partitioning
Persistence and Crash Consistency Considerations
Because FIX session correctness depends on ordered sequencing and the ability to recover session state, persistent storage behavior is a critical part of this architecture.
The system is designed to balance performance, correctness, and recoverability across both on-premise and cloud deployments, while remaining fully compliant with FIX protocol recovery semantics.
Persistence Modes and Flush Semantics
To support different latency and durability requirements, the system provides two persistence modes.
Persistence Model
FIX session state—including sequence numbers, message journals, and recovery checkpoints - is persisted to durable storage as part of normal operation. Writes are performed using buffered I/O, with explicit flushing at defined points, allowing deployments to balance performance and persistence strength.
The system supports multiple persistence modes to accommodate different operational requirements, ranging from ultra-low-latency trading to more conservative enterprise deployments.
Flush Semantics and Durability Considerations
In flush-enforced mode, critical session state is written using buffered I/O and explicitly flushed using fflush. This ensures that data is pushed from application memory into the operating system before write completion is acknowledged.
This approach provides stronger persistence characteristics than purely buffered writes, while avoiding the latency impact of fully synchronous disk operations. Final durability depends on the behavior of the underlying filesystem and storage platform, which may vary across environments.
Importantly, the platform does not assume that write acknowledgment alone implies immediate commit to stable media. Instead, it relies on FIX protocol recovery semantics to ensure correctness following unexpected interruptions.
Write Ordering Guarantees
FIX session correctness depends not only on persistence, but also on strict write ordering. The system enforces ordered writes at the application level:
- Message data is persisted before sequence numbers are advanced
- Recovery checkpoints are updated only after prior writes complete
- Session state transitions are serialized and deterministic
These guarantees are sufficient to preserve FIX journal integrity and enable reliable recovery, even when the most recent updates must be replayed.
Crash Consistency and Recovery
In the event of a process, host, or node failure:
- The filesystem and storage volume may roll back to the last successfully persisted state
- FIX session recovery uses persisted journals and sequence numbers
- Duplicate messages may be retransmitted, consistent with FIX protocol rules
- Session state is reconciled using standard resend and gap-fill mechanisms
This behavior aligns with common FIX deployments and avoids reliance on cross-layer transactional guarantees.
Cloud Deployment Considerations
When deployed in cloud environments, persistence behavior is influenced by the characteristics of the underlying block storage service. In practice, trading systems commonly use cloud block storage classes with documented durability and write-ordering characteristics—such as AWS EBS gp3 or io2, Azure Premium SSD, or equivalent offerings—based on provider documentation and operational experience.
These storage classes are widely used for latency-sensitive trading workloads when combined with appropriate persistence and recovery mechanisms.
Network filesystems introduce additional buffering and ordering complexity and are generally avoided for FIX session persistence unless explicitly validated.
Operational Best Practices
Based on deployment experience, the following practices are recommended:
- Use block storage services with documented durability and ordering characteristics
- Avoid shared or network filesystems for FIX journals unless thoroughly tested
- Monitor storage latency, as elevated write latency directly affects throughput and recovery time
- Select persistence mode based on latency sensitivity and operational risk tolerance
Our Experience
We have deployed this pattern across multiple cloud providers, consistently achieving recovery time objectives (RTO) under 60 seconds while preserving FIX session continuity and message integrity.
By combining persistent storage with Kubernetes’ self-healing capabilities, this approach minimizes manual intervention and operational complexity while providing a robust, production-ready HA solution for FIX connectivity platforms.